

Intro: From Quads to Graphs
1 介绍
中间语言不是凭空产生的。中间语言是程序员的表述到具体的机器代码的转换辅助,而且必须弥合大量的语义差异,例如从一个 fortran 90 的机器码操作到一个三地址码表述的 add 语句。在高级语言到机器语言的转化过程中,一个优化编译器会执行很多次的 pass 来优化 IR 。使用者希望优化编译器能把这一过程执行的迅速而又准确;而编译器的编写者则希望优化代码能够尽可能的简单易懂且便于维护。我们的目标是设计轻量级的 IR 来使得简单语句可以得到快速优化。
本文讲述了中间语言从 quad-based form 到 graph-based form 的转化历程。转化的最终格式类似于(当然不是完全相同)一个 operator-level 的 Program Dependence Graph 或者说是 Gated Single Assignment。最终的形式包含执行程序所需要的所有信息。更重要的是,这种图表形式明确地包含 use-def 信息,分析过程中可以直接使用此信息而无需计算。分析过程中 Transformation 会直接在 IR 的基础上修改 use-def 信息,而无需额外的步骤。这种形式的的 graph 是一维的结构,而不是像 CFG 包含两个维度(分别是 basic blocks 和 instructions)。这种一维结构可以在我们的算法中体现出来。
使编译器快速运行的一个原则是尽可能早地完成尽可能多的工作。这引导我们在 one-pass 的前端加入强大的窥孔优化。我们设计的 IR 允许施行窥孔优化,在某种情况下,这种做法可以和 pessimistic conditional constant propagation 起到相同的效果。
【窥孔优化】:
- 一种很局部的优化方式,编译器仅仅在一个基本块或者多个基本块中,针对已经生成的代码,结合CPU自己指令的特点,通过一些认为可能带来性能提升的转换规则,或者通过整体的分析,通过指令转换,提升代码性能。
【稀疏有条件的常数传播】:
- 稀疏有条件的常数传播(sparse conditional constant propagation)是一个优化的技术,常用在以静态单赋值形式(SSA)进行最佳化的编译器,它可以移除 dead code elimination 以及进行 constant propagation。
【常数传播】:
- 编译原理课上的常数替换优化
本文不是关于如何写成一个完整的编译器,而是分享一种设计思路,可以从传统的 IR 过渡到 graph-based IR。
1.1 Pessimistic-vs-Optimistic
我们将分析(和转换)分为两大类:Pessimistic & Optimistic。Pessimistic analyses 假设了一种最坏的状况(conservatively correct)并且尝试去证明,而 Optimistic analyses 假设了一种最好地状况。处理“循环”外的情形中,这两种技术产生的结果相同。而在处理“循环”的过程中,Optimistic analyses 会假设一些从循环的 back edge 中产生的“fact”成立,在之后的步骤中可能会得到证明;而 Pessimistic techniques 则在循环进行中不产生任何假设,只使用已经确定的条件。这可能不能产生 do not already have 的事实。
举个栗子,在常数传播*(上面介绍过)的过程中,optimistic analysis 先假设循环 back edge 上的一些 def_value 等价于 constant,如果假设被证明成立,则可以进行一次 constant propagation。如果假设不成立,也没有害处啊2333…循环体只需要结合更加保守的 information 进行重新分析就可以了。
而针对 Pessimistic analysis,循环 back-edge 的 def_values 都被看作为变量,当这些所谓的“变量”与 loop 中的常量合并时,根据已有的信息分析器只能确定该个变量是个变量,符合了一开始的假设,因此这种分析无法找到更多的常量。
但是,如果没有循环,两种分析都可以访问包含所有已有 fact 的代码,也就是说,两种分析都可以找到一组等价的 facts。为了有效地做到这一点,分析需要按拓扑顺序访问代码;且关于特定值的信息必须在使用该值之前收集。如果无序访问代码,则一些分析必须在没有所有相关 fact 的情况下进行。在这种情况下,我们发现 Pessimistic analysis 可以在 one-pass 算法中可以 usefully proceed,因为缺少信息的条件下编译器做出的假设(或者说是具体的优化)会较为保守,而针对 Optimistic analysis 我们必须反复 visit 该块无序代码来验证那些较为积极但“危险”的假设。
1.2 Optimizations-in-the-Front-End
由于我们可以在 one-pass 算法中进行 Pessimistic analysis ,因此我们可以在 Parseing 时执行此操作。当前端解析表达式时,分析器会为表达式指定一个保守值,并尝试根据以前解析的表达式来产生更好的 Parse 结果。只要解析器以拓扑顺序 Parse 代码,Pessimistic analysis 就像 optimistic analysis 一样好。我们观察到 Parser 按照拓扑顺序访问使用 if / then / else 结构构建的代码,在循环头或非结构化代码中,Pessimistic analysis 做出了保守正确的假设,这是非常令人开心的。
Pessimistic analysis 只需要我们在 Parse 代码时收集的 use-def 信息。编译器查看(并更改)包含某段 IR 的固定 region,在该块 region 外的区域代码在前者的产生和优化(transform)过程中不受影响。region 内的 IR 的转换同样也不依靠其他 IR_region 的信息。类似于窥孔优化的加强版。
通过在 Parse 中加入 Pessimistic analysis ,我们降低了整个程序的大小,而且减轻了后续优化阶段的工作量。(程序大小的缩减是因为我们通过 Pessimistic analysis 用一些新指令替换了原有的指令,后续优化阶段工作量的减少是由于我们提前完成了)
【use-def】:
- links at a value’s use site to the value’s definition sites
1.3 Overview
- Section 2:从带有基本指令块的传统CFG开始;
- Section 3:将这种表示适配到有明确的 use-def 信息的 SSA 格式
- Section 4:再在其中加入控制依赖(control dependencies)
- Section 5:使用C++的继承为我们的指令提供更多结构并加速其创建和删除
- Section 6:完全放弃CFG,取而代之的是处理 control 的指令
- Section 7:增强的窥孔优化
- Section 8:讨论如何处理各种 problematic 的指令特性(effect chain & memory dependence 以后有时间总结)
- Section 9:删除所有 control 信息
- Section A:lookat 基于终态 IR 的强大的 optimistic transformations
当我们在“进化”IR 时,我们也要“进化” pessimistic transformation technique,而且它最终会变成一种极其简单高效的优化技术,仅仅在分析循环和非结构化代码时较弱于 optimistic analysis。
2 In-the-Beginning
让我们来具体看看CFG。CFG 是一个有向图,其节点是 basic blocks,边表示 control flow。Figure 1 表示了基本块的实现,是一个双层壳结构。CFG 包含了两个特殊块分别是没有输入的 Start block 和没有输出的 Stop block。每个 Basic block 包含有序的 instr 列表。每条指令都是一个四元组:opcode、目标变量和两个源变量。当然有时候源变量数量可能是 0~3 不等(这种情况就不叫四元组了)。四元组的实现在 Figure 2 中,是一个单维结构:

在四元组指令的具体表示中,opcode 通常占用 1~4 个字节。每个变量都被重命名为一个相当密集的 machine integer,作为符号表的索引。源变量和操作码一起称为表达式。该四元组可能还包含指向当前 Basic Blocks 的下一个四元组的指针。

粗略地说,基本块的语义如下所示
- 每条指令都是按顺序执行的
- 指令的执行包括:
- 解析所有源变量
- 在这些源上执行 opcode 指定的原语
- 将结果赋给目标变量
- Basic block 的最后一条指令,不是写入目标变量,而是读取条件代码寄存器,并决定下面几个基块中的哪一个要执行(Jump condition)。
- Stop 块的最后一条指令必须包含 Return_opcode。
- start 块的第一条指令可以使用程序外部指定的 source(程序的输入)。
其余 IR 拓展功能按需添加。特别是子程序调用、内存(Load,Store)和 I/O 等等将进一步处理。
2.1 Pessimistic Transformations on Quads
到目前为止,四元组仍然缺少所有的 use-def 信息,即:A 指令中用到的变量由哪条指令进行赋值?在应用 use-def 信息之前,窥孔优化仅仅依赖于一个固定大小的指令窗口来检查和转换。该技术非常薄弱,因为其依赖【指令顺序】来”确保”变量的使用接近于变量定义,这是不严谨的。所有现代的编译技术都依赖于 use-def 信息,无论是局部(在基本块中)还是全局(在过程中)。
我们可以考虑将 Parse(甚至四元组的 generate )和 pessimistic optimizations 进行融合。During Parse,前端生成 basic blocks 和 instr。在生成 instr_A 时,前端立即在此 Block 中的前一个指令的上下文中检查指令,并立即进行窥孔优化,在 context window 中执行 instructions transform。Figure 3 展示了一种 during-parse 的窥孔优化。加入 use-def 信息等效于 context window 的拓展,允许非相邻代码的该类优化。

2.2 Use-Def Information
显然,use-def 信息将极大地改善我们的窥视孔优化。不仅如此,Use-def 信息对许多其他类型的优化也很有用。use-def 信息没必要和 source 变量名一起储存,仅依靠源变量名信息就足以生成 use-def chains。我们只需要在四元组中向后搜索就能找到 def 指令。但是,向后搜索可能很慢(程序大小呈线性)。更糟糕的是,向后搜索可能得到模糊的结果,因为程序中可能存在多种 def 可以 reach 相同的 use。为了解决这个问题,我们引入 SSA。
3 Static Single Assignment
适配 SSA 可以消除模糊的目标定义。在一个普通的程序中,一个变量可以沿着不同的控制路径(control path),或者说在不同的 basic block 中被多次定义。而在被转换为 SSA 形式时,某些 basic blocks 的头部会插入 Φ-function (在 4.1 中会具体描述),然后对所有的变量进行重命名。 Φ-function 被当作普通的的 instr 执行;且 Φ-function 的 opcode 与其他函数不同。Figure 4 展示了符合 SSA 的示例代码:

在重命名步骤之后,每个变量都精确地分配一次。且由于表达式只出现在赋值的右边,所以每个表达式都与一个变量(左值)相关联。也就是说,变量和表达式之间存在一对一的关联。因此,变量名可以当作“定义它的表达式”的直接映射(direct map)。 在我们的实现中,我们希望这种映射(mapping)越快越好。
在指令的具体实现中,我们会设计一个 field 用来存储源变量的名称(已经表示为 machine integers)。为了加快变量到定义的映射,我们用“指向变量定义指令的指针”(一个指向 instr 数据结构的指针)替换变量名。现在,执行从变量名到定义指令的映射需要单个指针,在这种方式下,use-def 链是显式编码的。Figure 5 展示了这种新的指令格式:

我们现在有一个从变量和表达式到指令的来回抽象映射。这意味着我们不需要额外的指令来对已经定义的变量名进行编码——转而使用上述的映射关系即可。因此可以删除 dst 字段(优化的时候不再需要具体的左值信息,仅依赖于 use-def )。但是,During Parsing,前端也需要从变量名称到指令的映射(前端的变量名称表现为 machine integet)。于是需要 vn 到 instr 的映射表(parse 过程)。考虑到已经存在 vn -> integer 的映射,我们需要构建一个 integer -> instr 的映射。每次窥孔优化后我们都会更新该 map。
Figure 6 展示了新的 Parser 接口。由于现在我们使用的是 use-def 信息而不是 context window,因此我们不再需要 prev 指针。

【note】这里的 dst & src 都是 integer ,并且对 instr 隔离。
3.1 Building SSA Form
我们现在使用相对保守的方法来构建 SSA。我们的方法不需要分析整个程序,当然,在我们仍在 Parse 程序时这也是不可行的。变量的每个定义都被重命名为定义指令的地址(vn->instr | line 5),而且每个原始变量都映射到一个 integer 索引(vn:integer | line 3&4),我们在索引的基础上使用一个简单数组来映射 def( ==arr_of_mapping==[integer]=def | line 3&4)。当我们找到现有变量的新定义时,我们更新 ==arr_of_mapping==.
在每个 Basic Block 的开头,如果我们将要处理同一个变量的两个定义时,我们就会插入 Φ-function。在嵌套的 if / then / else 结构中,我们将解析所有通向 merge point 的路径。然后检查所有变量以更改定义并且按照需求插入 Φ-function。在 loop head 和 labels 位置,我们必须先假设所有变量都定义在我们尚未解析的路径上,这造成我们需要插入很多冗杂的 Φ-function 。但该算法依然很快。
3.2 Pessimistic Optimizations with Use-Def Information
现在 use-def 信息已经嵌入到 IR 中。有了这些信息,我们就可以分析相关指令,而不管它们的顺序如何(也就是可以放弃context window ?maybe),而且这种分析会比以往更加有效。Figure 7 展示了我们使用 use-def 信息的一个窥孔优化实例:

【参考 Figure 5 加速理解】
(during codegen当一条指令的状态是 unused (not codegen),我们总是返回一些 replace指令。replacement_instr 可以是之前定义的指令(可以理解为use original def )。使用以前定义的指令而不是创建一个新的指令会缩小我们的代码大小(好像同时也会减轻优化的工作量)。我们下面列举了一下优化:
- Removing copies: 直接使用原始值而不是 copy。
- Adding two constants:通常来说,只要原语的 source 均为constant,那么在编译时就可以把结果直接优化为 constant,也就是依靠计算机的机器指令来优化。
- Adding a zero: not add,use original
- Value-numbering: value 编码会帮我们删除一些等效表达式,like line 5_if。所使用的方法是哈希表查找,其中 key 是从 data-input(or src)和 opcode 中计算出来的。因为我们 instr 结构中没有任何 control-data,我们可能会得到两个等价的但是毫不相关的表达式(不同的 control-path)。这种情况下,简单的 replace 就颇为不妥。为了修复这个问题,我们需要在每个 Basic Block 的末尾都刷新一遍 hash table。
- Subtracting equal inputs:
3.3 Progress
我们取得了很大的进展,不仅从instr_format中删除了 dst 字段,而且收集了 use-def 信息以供以后的 passes,并加强、加速了窥孔优化。然而,我们可以 do better。对于基本块中的指令,我们仍然有一个固定的顺序,操作逻辑还是依赖于 ==next== field。然而,当一个 Basic Blocks 被执行时,块中的所有指令都被执行。而对于超标量或 data-flow 机器,只要它们的 input dependencies 得到满足,就应该允许以任何顺序执行指令。 要纠正这一点,我们需要考虑指令是如何排序的。
4 Control-Flow-Dependence
在到目前为止描述的 IR 中,基本块包含有序的指令列表。在某种意义上,这代表了 def-use 控制信息。basic block 从某种程度上 define 了control-flow,然后 instr uses that control。我们需要做的是抛开 basic block 这种隐式 control flow,转而为每一个 instr 建立相应的 control data。消除串行化控制依赖关系允许在 Block 中的 instr 可以不按顺序执行,只要它们的其他数据依赖关系得到满足即可。此外,我们希望这种数据关系与我们的依赖表示保持一致,并显式地使用 use-def 信息而不是 def-use 信息。
基本块中指令的有序列表被表示为 linked list 形式。每条指令都包含指向下一条指令的指针。我们用一个指向 Basci Blocks 结构本身的指针替换这个 next pointer,并将此指针视为指令的另一个 source of input:the control source。此时,每条指令都有 0~3 个数据输入和一个 control input。Figure 8 描述了这种新的结构。在该示例中,我们仅展示了一个基本块,但其中的 data inputs 可以位于任何基本块。

【左侧指针代表 control】
4.1 More-on-Φ-Functions
首先明确什么是 Φ-Functions。举个栗子:
这是一个适配了 SSA 的 CFG。现在面临的问题是:
- W2 & Z1 的 Y_source是那条路经上的?
因此我们引入 Φ-Functions :这个函数将分析控制流信息,通过选择y1或y2来生成y的新定义y3。
也就是这样: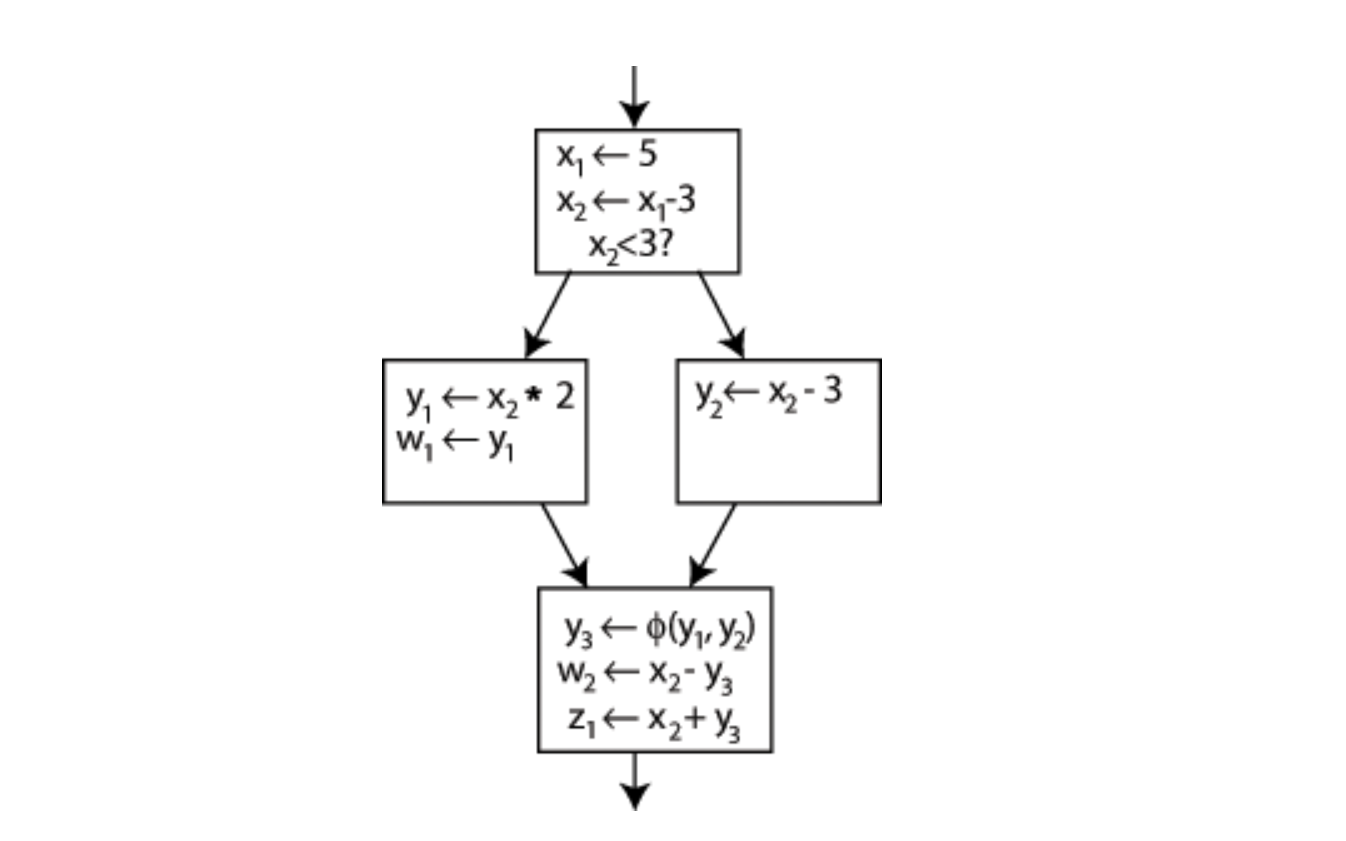
—介绍结束
我们依然需要 CFG 的 edges 来帮助判断“模糊节点”并在其中加入 Φ-Functions。我们需要将来自相应基本块的 control input 与 Φ-instr 的每个 data input 相关联。这样做意味着 Φ-instr 将具有一组 input pair(two element):分别是 control dependence 和 data dependence。这种具有复杂语义的结构显得很笨拙。下面我们看一种全新的结构。
我们将 Φ-instr 拆分成一组 Select 指令和一个 Compose 指令,每个指令都有简单的语义。Select 有两个 input: control dependence 和 data dependence。Select 计算的结果取决于 control。如果 control source 没有被执行,也就是说对应的 Basic Block 没有被 exec,那么不产生任何 value 结果。否则,data value 将被 pass up(自造词组2333)。紧接着,Compose 将 Select 的所有结果作为 input,并且 pass up 产生 value 的 Select 的结果。如 Figure 9 所示:
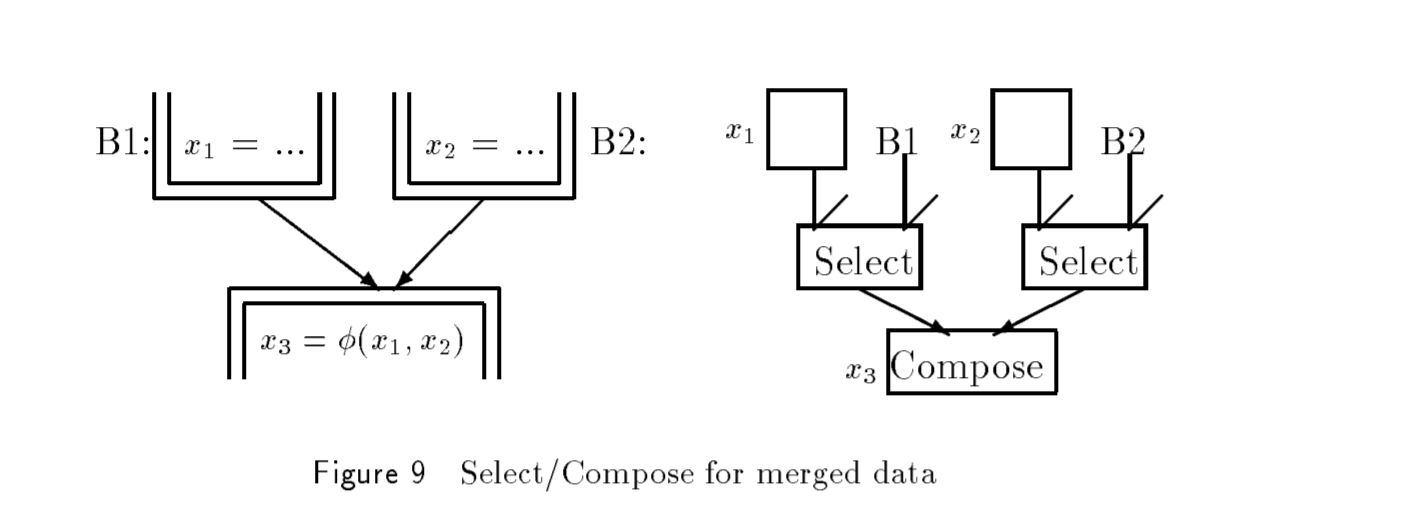
WARMMING!!!这些指令(Select & so on)没有 Run-time 操作,而且它们不是机器指令。它们的存在仅是为了帮助编译器理解程序语义。当最终的机器代码被fully generated,Select / Compose序列将被 folded back 回 basic blocks & CFG。
4.2 Cleanup
此时我们的 instr 已经较为完美了,其 use-def 信息包含了 data 和 control(针对use-def-of-control,可以理解为常规控制流图反过来的逻辑链)。另外,我们还有足够的信息保证 IR 的可加工性(因此很容易修改,例如,merge dead path)。但是,我们现有的的 Inst 类很难很好的抽象出各种不同的指令。我们将在下一节中讨论这个问题。
5 Engineering-Concerns
我们注意到我们可以有好多不同的指令,每一种指令都有不同数量的 input。像 Compose 指令,可能有任意数量的输入;Negate 指令只有一个 input;而 Constant 指令(定义 one simple int)需要保存正在定义的 constant 的值,且没有其他的 input。为了处理所有这些差异,我们将 instrument 的定义分解为单独的、继承自基类 Inst的 class。 Figure 展示了了新的基类和一些继承的类。
我们使用的是函数式编程风格。我们创建并初始化了所有对象,但从未修改过。为了获得编译器对这种编程风格的支持,我们在类定义中插入了适当的 const 限定符。
- 【NOTE】 纯函数式编程中的变量不是命令式编程中的变量,而是存储状态的单元,是不可变的(immutable)。也就是说不允许像命令式编程语言中那样多次给一个变量赋值。

5.1 Virtual-Optimizations
在 Figure 7 中的窥孔优化实例函数中,c++ 代码对每个对象类唯一的 opcode field 进行 switch。但在一个完整的实现中,switch 语句会变得相当巨大。另外,单个 opcode 的语义将被分为不同的 sections;一个 section 用于类定义,另一个用于窥孔优化。但我们更喜欢将 opcode 的所有语义放在一个地方:类成员函数。在 Figure 11 中,我们将 peephole function 分割成针对特定 opcode 的 virtual functions。

要使哈希表起作用,我们必须能够 hash instr 和比较指令。不同的类封装指令具有不同的哈希函数和不同的比较语义。举个栗子:ADD 的source value 无论顺序如何其整体散列值应该一致。Figure 12 展示了 virtual hash 和 compare functions。

5.2 Faster-Malloc
每次执行新指令时,我们都会调用操作符 new 来获得存储空间。但他反过来又会调用 malloc,可能相当耗时。此外,窥孔优化经常删除新创建的对象,需要调用 free。我们通过为 Instr 类 hook 特定于类的操作符 new 和 delete 来加速这些频繁的操作。首先我们需要为这种 replace operate 分配一个 arena。Arenas 中包含具有相似生存周期的堆分配对象(instrs)。生存周期结束后,我们会 delete 整个 arena,从而快速地 free 掉内含的所有 object。如图13所示:

arena->next = pre_arena
Allocation 会检查当前 Arena 的空间大小。如果 Arena 没有足够的空间,则会在其中添加另一块内存。如果对象 fits,则返回对象地址的当前 hwm ,具体看代码。整体的 GC 风格是用内存指针的移动代替实际的内存分配释放。其中 Arena 的扩充以及 chunk chain 的释放算是唯二耗时的内存操作。
5.3 Control-Flow-Issues
通过上述这些更改,我们的 IR 的整体设计终于变得清晰起来。每条指令都是一个独立的C++ object,其中包含确定 instr 如何与其周围的程序交互所需的所有信息。instr 的主要字段是 opcode。opcode_class 决定指令如何传播常量、处理代数恒等式并找到与其他指令一致的地方。为了使 IR 适配一种新的操作,我们需要定义一个新的 opcoded 和类——该类需要采集 data field 作为 intr’s input,而且需要提供窥孔优化以及 value-numbering 接口(hash),而不需要对窥孔或 value-numbering 本身进行任何更改。所以现在的 IR 具有相当强的可维护性。
6 Two-Tiers-to-One
我们的 IR 有两个不同的 level:top_level,CFG 包含 Basic Blocks;bottom level,Basic Blocks包含 instr。过去,这种 seperate 对于 concerns 的分离很有用—— CFG 处理 conrtol flow,基本块处理 data flow。但是,我们希望用相同的机制处理这两种 dependence,因此我们需要消除这种壁垒。
先来看看 instr 怎么处理。抽象点来说,每个 instr 都可以当作一个 node 。 instr 的每个 input 都表示从定义指令的节点(def)到该指令的节点(use)的一条边(def -> use 边)。edge 的方向正好和 instr 中的 input_pointer(use-def chain)的方向相反。这并不矛盾:我们恰好正在定义这样一个 abstract graph。像 Figure 14 所描述的那样,这个 “graph”的具体实现是从 sink
到 source (use to def) 的 edge 遍历,而不是从 source 到 sink (def to use)。

为了确定何时执行,每个 instr 都要从 Basic Blocks 获取一个 control input。如果 input 是抽象图中的一条边,那么基本块必须是抽象图中的一个节点。所以,我们定义一个 Region instr 来替换基本块。 Region 指令将来自每个predecessor block 的 control 作为输入,并产生 merged control 作为输出。
由于 Region instr 作用是合并 control inputs,因此不局限于 separate control input 来确定何时执行。因此 control input 字段就可以移动到具体的 class-specific instr_class。Figure 15 展示了这种变化:

如果basic blocks 以条件指令结尾,我们就把条件指令换作 IF。Figure 16 展示了 IF_instr
是如何工作的。
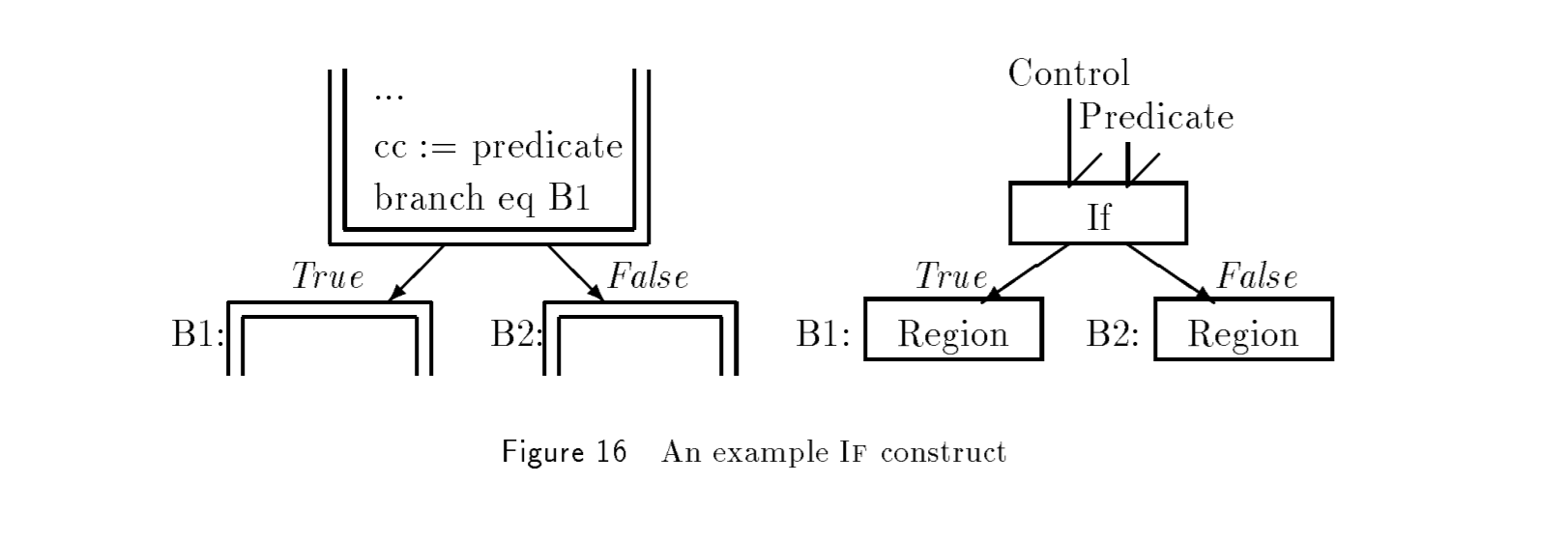
左侧是这样的逻辑:predicate 提供 condition 判断语句,branch 将 control-flow 引导至不同的 block。然鹅通过显式的 control edge,IF instr 接受 control input 和 predicate 输入,然后产生 out-control 传递给不同的 Region。
【NOTE】这种转化后,其实该 graph 还是双层网状结构,只不过操作逻辑变成单一维度。
6.1 A-Model-of-Execution
在放弃基本块和 CFG 之后,我们的执行模型是什么?我们从中间表示的设计历史中获取线索。其实和四元组一样,我们的 IR 模型还是有两个分开的部分。就像 Figure 15 源码所述,我们只是在操作逻辑相同的单个 graph 中嵌入了两层 representation 维度。也就是说,我们的优化操作并不将这两层 subgraphs 区分开来,只是针对不同的 opcode 有不同的接口。
control subgraph 使用 Petri net 模型。 随着 exec 的进行,control token 在节点之间移动。这反映了 CFG 的工作方式:control flow 即 Basic block exec 顺序。control token 只存在于 Region / If / Start 指令中。Start 基本块被替换为产生初始 control token 的 Start 指令。随着指令的 exec,control token 也会随之前进。如果该 token 遇到了 STOP 指令,则执行停止。由于我们是使用 CFG 构造了当前 graph,所以我们确保在当前指令的所有传出边(control out)上只存在 Region / If / Stop 。
data subgraph 不使用基于 token 的语义。 data node 的输出是其 input 和 function(opcode)的直接反映。因为没有记录状态的 token 存在,因此就不存在 Petri net。在每个 out edge 上,data value的数量都是无限的。直观地说,当一条指令需要 data instr 的值时,它会沿着 use-def 追溯到该 instrs,并读取存储在那里的值。在无环图中,这种根到叶的变化波动非常快。当数据值的传播趋于稳定时,control token 移动到下一个 Region 或 If 指令。Graph 中不可能只包含 data node ,每个循环都有 Compose / Region 指令
两个 subgraph 在两种不同的指令类型中混合:Compose/Select 指令和 If 指令。Compose / Select 组合读入 data 和 control ,并输出 data value。Select 不使用 control token,但会检查是否存在 control token。Select 的out 只有两种,一种是 data input 的拷贝,另一种就是 no-value。这当然取决于 control token 的存在与否。 Compose 输出它们的 previous value 或 present value。
IF 指令同时接受 data 和 control token ,并持有 True/False control token。两个可能的后继 region 只有一个能起到作用。在 Section 8.1,我们修改了 If 指令,使其行为更像其他 control handling 指令:给与两个后继,只有一个接收 control token。【图 9 和图 16 可以结合】
Figure 17 展示了一个简单的循环。Region 指令代替 Basic Blocks 作为 head 来处理该 loop 的 control-flow。Region & If 构成 loop 的简易 control 框架;Select & Compose 用来处理 SSA 形式下的变量混淆,接受的 control 参数分别为开始时的 Start 和 经历了 loop 的 If-false-control-out,对应的 data input 分别为 i0 和 i2。注意判断语句是作为 If_input 的 predicate ,outer 为 data。
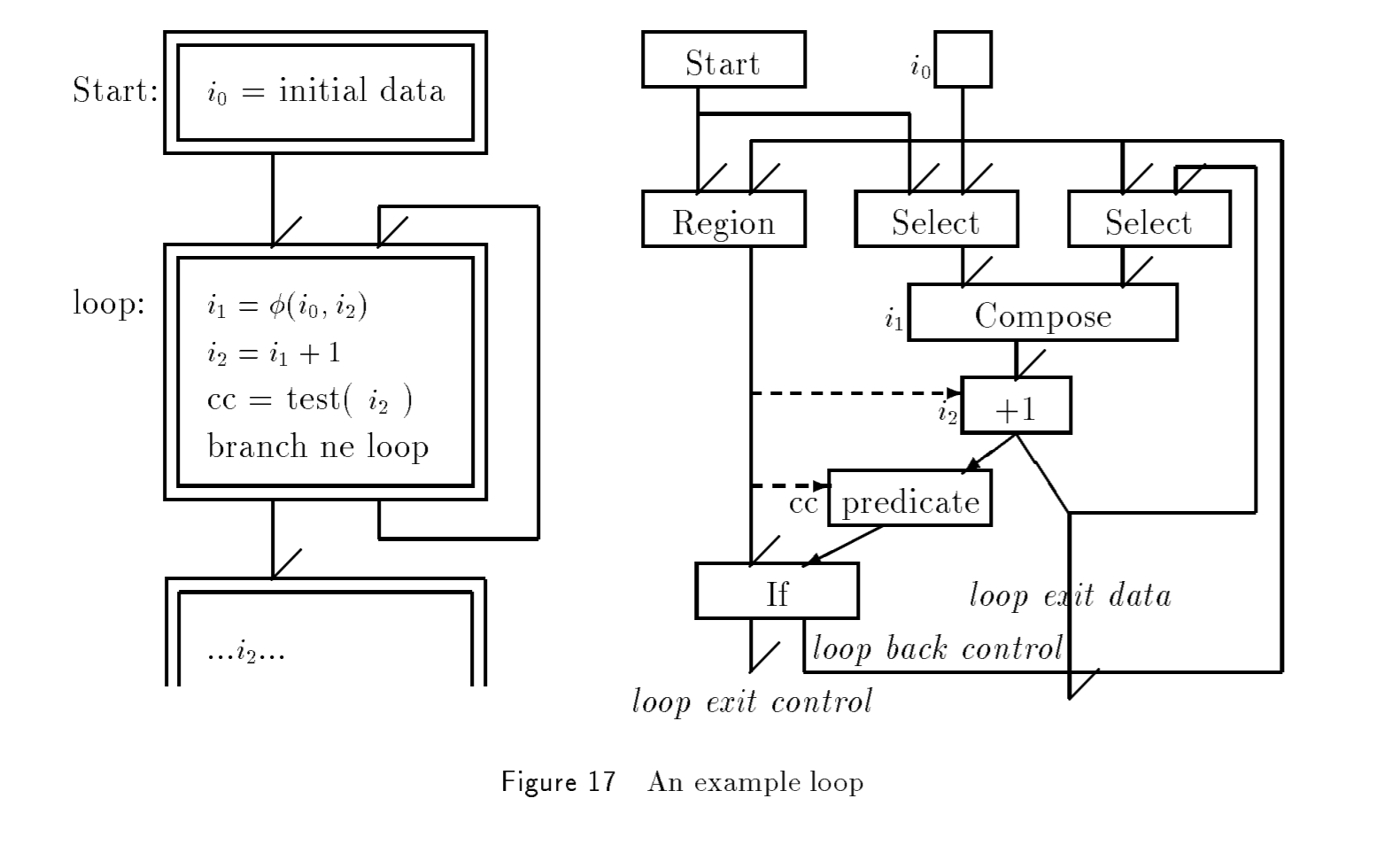
6.2 Control-Based-Optimizations
把 control 信息作为显式输入意味着我们可以在优化中使用它。一个具有 Constant test 的 IF 语句只能产出两个 control outs 中的一个,其中“live”边的 control out 就是 If 的 control in 的拷贝,而 If 则会在 dead 边的 head 部分输出 NULL(dead-out)。在我们讨论如何处理 If 的两个不同输出之后,图 24 提供了执行此操作的代码。(现在不急)
在做针对 ADD 的窥孔优化时,我们可以检查我们正在 Parse 的代码是否已经处于 dead 状态并立即将其删除。例如,当 DEBUG code 被编译出来,程序员将常量值传递给各种 flag 位时,可能存在某些选项 flag 为 0 的状况。然后相应地,If 产生 dead out,之后的 code 通过判断 dead out 将相应的 instr 删除(包括但不局限于 ADD)。 如 Figure 18。

注意,我们返回 NULL 作为 unreachable instr 的定义指令。这意味着任何优化 unreachable instr 的尝试都将使用 NULL,fail 无疑。这种直觉是正确的:无法访问的代码永远不会执行,所以我们永远不应该尝试使用这样的代码。为了简洁起见,我们将在以后的示例中跳过对于 control inputs 是否为 Null 的检测。使用这些 NULL data values 的 Select 指令的 control inputs 同样为 Null(Null data 存在于 dead-path),因此也是 unreachable 的(从 control-flow 角度)。Compose instr 检测来自 Select 的 input:如果为 Dead,则直接移除。
Region 和 Compose 指令可以以类似的方式进行优化。Null input(dead-path)可以直接移除。如果 Region 和 Compose 的 input 是单一的,那么可以直接移除该 instrs(control token 均为拷贝)。在 Parse 过程中进行这些优化需要前端确认之后没有其他的 control path 可以到达 merge points。针对 if / then / else 这种结构化代码对应的 merge points,与其有关的所有 control-path 都是已知的。在解析完到达 merge points 的所有路径之后,可以优化 Region 和 Compose 指令。而针对 label 对应的 merge point,前端只有在全部解析完 label 所在的 scope 才会进行优化。
6.3 Value-Numbering-and-Control
如果我们把 control input 信息嵌入到 value numbering’s hash 和 key-compare functions 中,那么我们就可以避免位于不同基本块的等价 instr 的混淆,因此也就不需要再每个基本块结尾进行 hash table 的 flush。然鹅,这依然还只是本地的 value numbering。放弃 control 并且做到全局的 value numbering 我们将在 Section 9 中介绍。
6.4 A-Uniform-Representation
现在,我们使用了相同的 Inst 类来表示整个程序。control 和 data flow 统一表示为图中节点之间的边。从现在开始,我们会对 graph 进行细化,但我们不会对其进行任何重大更改。
在完成四元组到 graph 的转换之后,我们得到了什么?在下一节中,我们将看到有关窥孔优化的通用代码。此代码适用于所有指令类型,添加新的指令类型(或操作码)也不需要对其做任何更改。其工作包含:value-numbering ,constant folding 和 eliminating unreachable code.
7 Types-and-Pessimistic-Optimizations
我们以前的 vpeephole 结合了 constant folding 和 identity-function(对相同函数进行优化)。在 Section 10 中,conditional constant propagation 不能使用 identity-function 优化而且只需要 constant-finding 代码。所以我们 break up 原本 vpeephole 中的优化函数,将其分为两种:进行 constsnt folding 的 Compute 以及进行 identity-function 的 Identity。Compute 产生的 constant 被储存在 type 结构中。
type 就是一组值。我们感兴趣的是在 run-time 中的 value 以及类型。其结构如下:

上下两个符号与 control flow 相关联,分别代表 control 的 unreachable 和 reachable but not constant。
identity-function 优化和 Compute 的代码如图 20 所示:
如果 Identity 判断指令 x-instr 是某个其他指令 y-instr 的等效函数,则删除 x 并返回 y 来作为 x 的替代。删除 x-instr 并返回 y-instr 的操作仅在其他地方没有针对 x-instr 的引用的情况下有效(否则我们有空指针指向 x)。 因此,只有在我们最近在 Parse 期间创建了 x 时才能使用 Identity 代码。由于我们的目标是 during parsing 的优化,因此无伤大雅。
// 如果 instr 的 src 的 type.height 其中一个为 TOP,则无法继续常量折叠; 如果 instr 的 src 的 type.height 其中一个为 bottom,则无需继续常量折叠
7.1 Putting it Together: Pessimistic Optimizations
我们的下一个窥视孔优化器的工作原理如下:
- 为每个 instr 进行 Compute Type
- 如果指令的类型是常量,则用 Constant 指令替换掉。先删后填使 new 和 delete 可以重复使用内存。这也意味着我们需要在删除之前保存相关的常量。
- 对 instr 进行 Value-numbering,尝试寻找以前存在的可替换的指令。我们在 old instr 上无需使用 Identity-function 优化,因为在其进入哈希表之前肯定经历过该类优化。
- identity-function 优化。
- 如果我们没有找到替换指令,我们必须计算一个 hash value,并将其插入 hash table。
- 返回 optimized instruction

7.2 Defining Multiple Values
我们已经实现了我们的设计目标之一:使窥孔优化的代码简单和直接。根据我们的经验,这个窥孔优化将程序峰值内存大小(和运行时间)减少了一半。
然鹅,在我们现在的 IR 中对 IF 的处理还不够完善。IF 产生两个 seperate result。 If 的 user 被分为两组,具体的访问取决于他们可以得到的 result。到现在为止,没有任何一个非 If instr 具有这样的指令行为。在下一节中,我们将介绍几种产生多个值的指令类型,并尝试找到一种统一的解决方案来选择该类 instr 的 result。
8 More Engineering Concerns
在最初的基于四元组的实现中,有好几种定义多个 value 的 instr。 例如,设置条件代码寄存器以及计算结果(即减法)和子程序调用(至少设置结果寄存器,条件代码和内存)的指令。以前,这些指示是在特别的 basis 上处理的,而如今我们要使用更正式的方法。
单个指令,例如 If ,产生多个不同的值( true/false control-out )是一件很令人头疼的问题。当我们引用这样的一条指令时,指的是哪个输出呢?我们通过引入“单个元组值(tuple)”来统一代替这样的 multi-defining 指令产生的 outs 来解决这个问题。然后我们使用 Projection 指令去掉我们想去掉的 piece of the tuple。每个 Projection 指令从 defining instruction 中获取 tuple 并生成一个简单 value。
Projection instr 没有 run-time 操作,换句话说,其运行在 zero cycles。如果都用 machine code 表示的话,tuple-producing 指令就是一个产生多个 result 的 machine code。而 Projection 仅仅是为不同的 result 指定不同的名称。
tuple-producer 的工作之一就是为 Projection Compute a new Type。该 Projection 指令的 Compute 代码通过将 Projection 传递给 tuple-producer 的 Compute,让 tuple-producer 确定 Projection 的 Type 并且使用该结果。由于 non-tuple-producing 指令永远不会成为 Projection 的目标,因此默认值是一个 ERROR,如图 22 所示。Identity 的处理是类似的。

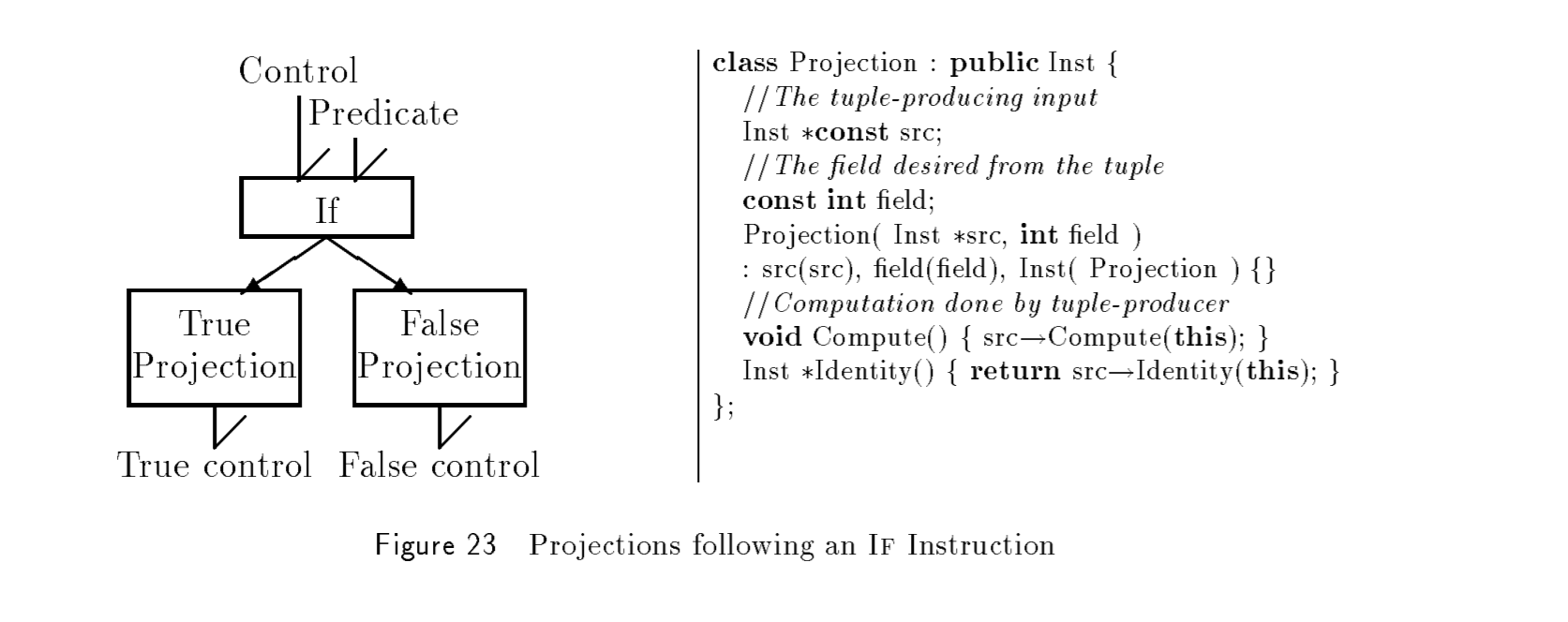
8.1 If Instructions
If 指令接收 predicate 和 control input,并产生 true/false 两个 control out。分配给
True/False-Projection 并插入 Region 作为后继。示意图和代码如下:

8.2 Projection Instructions
通过对 Projection 的定义,填补了我们模型中的一个主要空白。我们现在有关于 peepholer 如何查找和删除 unreachable code 的具体代码。到目前为止,每个 data 指令都包含一个 control input ,该 input 从本质上定义了指令属于哪个基本块。但在许多情况下,我们并不关心指令被放置在哪个块中,只要它在数据依赖关系得到满足和任何 uses 之前被执行即可。下一节中,我们就要删除 control input。
9 Removing Control Information
在我们的模型中,我们要求每个数据计算都有一个 control input ,以确定数据计算什么时候应该执行。事实上我们可以从数据计算中删除 control input ,并且完全依赖于 data dependence 。当然,这样做优缺点并存。优点是:
- 图中较少的 edge 意味着较小的图形、较少的构建和操作工作。
- value numbering 的工作原理是找到congruent(一致性的)sub-graph 段,其中 congruent (一致性)被定义为“一致性输入上的相等函数”。而一旦失去了 control input ,hash 就难以保证来源的差异性。所以 pessimistic value numbering 就要和 global value numbing 一样强。
- 缺少控制输入时,只剩下数据输入。计算中不再有”所属的基本块”的概念。跨基本块执行代码移动的调度器不需要知道指令有多大的自由度;
这些信息是显式的。
缺点是:
- 好无聊啊不想写2333
10 Optimistic Transformations
Optimistic transformations,例如稀疏条件常数传播(Sparse Conditional Constant Propagation),会在优化过程中做出 optimistic assumptions 并尝试证明,有时可能需要分析整个程序以进行验证一个猜测。因此,我们需要在每条指令中保留有关当前 assumptions 的一些信息。该信息存储在 Type 字段中, Type 字段由前面定义的 Compute 设置。
我们依靠 pessimistic analysis 避免的这种 global analysis 的另一个条件就是需要就是 def-use edges。到目前为止,我们所有的优化都只能在给定一个 instr 和它的直接 uses 成分(即给定 use–>def edges) 条件下执行。对于 optimistic transformations ,我们假设所有指令都是 undefined 以及所有的 code 都是 unreachable 。然后从 Start 开始,我们开始逐步验证并修改这些假设。当我们发现一条指令定义了除 “top” 以外的值时,我们就必须 inspect 所有使用该值的指令的 assumptions。因此我们需要 def-use edge。
因为我们需要全局(批处理)算法的 def-use edges,所以我们要一次性找到它们并将 single insruction 的 def-use edges 按照顺序放入一个大数组中。 要访问 该 instr 的 edges,我们需要指令中的 start 和 length 部分。因此我们为 instrument 引入了两个新的 field :def_use_edge 和 def_use_cnt(count)。
我们通过遍历 graph 的 use-def edges 来找到 def-use edge。要进行图形遍历,我们需要一个 visit flag,一个 use-def edge 计数器,以及一个通过 index 访问 use-def edges 的函数。新构建的 instr 如下图所示:

我们在图 27 中构建了def-use edge。我们需要使用 Stop 指令和 use-def edge 的数量作为输入以及构建一个空数组来保存 def-use edges。首先通过对 Graph 的一次遍历 pass,count 每个 Inst 的 def-use edges。在此步骤中,我们还将所有 Type 初始化为 “Top”。在第二次 pass ,我们将 edge value 存储到数组中,将数组部分的开始部分存储到 Inst 里去。因为我们从 Stop 指令开始所有的遍历并且只沿着 use-def edges 行进,所以我们不会访问到 dead code。也就是说,我们也不会将其将其表示出来。这就等同是在 SCCP 之前进行了一次 dead code elimination。

接下来,我们运行 SCCP。我们把 start 指令放在 worklist 上。然后我们进入一个简单的循环:我们从 worklist 中提取一条指令,为其 compute 一个新的 Type ,如果与默认值不同,则将该指令的所有 uses 放回 worklist 中。当该 list 清空时,工作就完成了。
10.1 The Payoff

Summary
为了得到更快的 optimiser,我们决定在 front-end 做一些工作。我们推断,在 Parse 过程中进行的窥孔优化将减少 IR 的大小和后期优化阶段的开销。
我们以SSA形式进行了前端构建。因为我们在 Parsing 时无法分析整个程序,所以必须插入很多的 Φ-Functions 。我们注意到 variable names 是程序表达式的一对一映射。,因此我们用 instr-pointer 来进行替换。此时表达式中的 name 字段就显得毫无用处,因此我们果断的进行 dst 的删除。我们还观察到了 basic blocks 内的隐式控制流,我们对此进行了显式控制(因此需要进行优化)。我们还发现,在尝试编写 unreachable code elimination 的窥孔优化时,我们的模型是 non-compositional(分离操作的属性,可进行显式的操作),我们通过在 Φ-Functions 中引入 control 并将其分解为 Select 和 Compose 两条指令来解决这一问题。
紧接着我们利用了c++ 的继承机制,并将 Insts 重新构造为单独的类以用于每一种 instr。我们还插入了专门的 new 和 delete 功能。
这时候我们注意到 Basic Block 结构只包含了一些 typical dependence,这和一个典型的 instr 没有什么两样,因此我们直接将其替换为 Region 。因此我们一直使用的窥孔优化现在允许我们除常规的 constant fold 和 value numbering 之外进行 unreachable code elimination。
我们将每条指令的 peephole 分解为 constant folding(compute)和 identity-function 优化。其中的 constant folding 在 global opt 中被使用。
最后我们优化了SCCP。
Reference
From Quads to Graphs: An Intermediate Representation’s Journey



