

Intro: Analysis of Ignition && IC
Overall Design
Ignition 本身由一组 Bytecode Handler (CSA 形式的 Code Stub )组成,每个 Bytecode Handler 处理一个特定的 Bytecode ,并调用下一个 Bytecode Handler。这些 CodeStub 是用一种高级的类汇编结构( 便于保持平台无关性 )编写的,由 CodeStubAssembler 类实现,最终由 Turbofan 编译。
因此,这种高级的 Codestub 只需要编写一次就够了,为了实现特定平台的编译只需要使用 TurboFan 为每个架构生成机器指令即可。在 Ignition 准备完毕后 ,每个 V8 的 isolate 中都包含一个全局的 interpreter dispatch table,其中存储了指向所有 Bytecode Handler 的指针,并且该指针由 Bytecode Value 索引。
在一个函数经由 Igntion 解释执行之前,我们需要先得到对应的 Bytecode。Bytecode 的生成任务交给了编译器开始的时候运行的没有一点优化措施的 BytecodeGenerator 。这个部分的实现和一般的编译器差不多,生成 Bytecode 主要是靠一个 AstVisitor 遍历函数的 AST,为每个 AST 节点进行 codegen 得到 bytecode。然后,生成的字节码将会存储在对应函数的 SharedFunctionInfo 上,并且函数的入口地址将被设置为 InterpreterEntryTrampoline 地址,这里的 InterpreterEntryTrampoline 同样是一个 builtin Stub。当然,在这一步之前 Ignition 中的大量 Bytecode Handler 就已经被 turbofan 编译完成了。
由于已经设置了入口,因此当 Runtime 调用一个函数的时候会首先调用到 InterpreterEntryTrampoline。该 Stub 做了一些函数解释运行的初始化工作,比如设立函数栈帧,并且会根据 SharedFunctionInfo 中 BytecodeArray 中的字节码调用 interpreter dispatch table 中对应的 BytecodeHandler。之后通过自动机形式的执行流程来针对每一个 Bytecode 进行解释执行。
Ignition 是一个基于寄存器形式的解释器。这里的寄存器并非 CPU 上的寄存器,而是为了实现 VM 的基本功能而模拟出来的寄存器,并嵌入 Bytecode 的设计模式中。需要额外说明的是,Ignition 维护了一个隐式寄存器 accumulator,也叫做累加器,其设计目的是为了字节码的轻量化,但无疑增添了设计难度。
Generation of Bytecode Handlers
每一个 Bytecode Handler 都是由 Turbofan 独立生成且作为 code object 存在。而且这些 Handler 的源码均通过 InterpreterAssembler 类( CSA 子类,封装了一些 Ignition 需要用的高级原语 )写成了 Turbofan graph 的形式。例如:1
2
3
4
5
6void Interpreter::DoLdar(InterpreterAssembler* assembler) {
Node* reg_index = __ BytecodeOperandReg(0);
Node* value = __ LoadRegister(reg_index);
__ SetAccumulator(value);
__ Dispatch();
}
值得一提的是,由于这种自动机模式的执行特点,因此在 Handler 的 dispatch 过程中需要保存一些全局变量,例如 bytecode 的 index 信息。为了传递这些信息,他们被设计为存储在固定的寄存器内。
在对应每个 BytecodeHandler 的graph被生成后,他们将会进入 turbofan 的简化版 pipeline。最后分派给 interpreter table 中对应的表项。

Bytecode Generation
让我们回到第一步:如何得到一个函数的 Bytecode?
得到 Bytecode 的常用做法就是遍历 ast,并对每一个 Ast node 进行 codegen。具体来说:
- BytecodeGenerator 遍历 ast node
- BytecodeGenerator 使用 BytecodeArrayBuilder 来具体生成格式良好的 BytecodeArray
Interpreter Code Execution
由于 Interpreter 是一个基于寄存器的解释器。Ignition的入口点是函数的InterpreterEntryTrampoline , 该 builtin stub 会开辟适当的堆栈帧,并加载预留的机器寄存器(例如,BytecodeArray 指针、interpreter dispatch table 指针)
something important: Property loads / stores
BytecodeArray 通过内联缓存( IC )加载和存储 JS objects 对象的属性值。Interpreter 使用和 Turbofan 一样的 ICs 系统,均直接在 TypeFeedbackVector 上操作。
Bytecode Handler 将函数的 TypeFeedbackVector 和与操作的 AST 节点相关联的 type feedback slot 一并传递给 IC stub。IC stub 可以更新 TypeFeedbackVector 中的该 slot 条目,并支持 type feedback info 的学习型反馈。
下面介绍一下内联缓存,也叫做 IC
Inline Cache
【+】 https://ponyfoo.com/articles/an-introduction-to-speculative-optimization-in-v8
【+】 https://mrale.ph/blog/2012/06/03/explaining-js-vms-in-js-inline-caches.html
【+】 https://mrale.ph/blog/2015/01/11/whats-up-with-monomorphism.html
【+】 https://www.youtube.com/watch?v=u7zRSm8jzvA
Ignition 收集的 feedback 信息被储存在 Feedback Vector 中。这个特殊的结构体被链接到 closure 里,包含了若干 slot 用来存储 IC 信息。
对于一个任意的 Object,在 Runtime 中计算其中某个属性的偏移是很耗时的。因此我们只希望进行一次查找,然后将该 object 的 map 作为索引将该属性的偏移放入 slot 内。如果下次我们看到了相同 map 的 Object,就可以直接获取属性的位置。
IC 分为单态内联和多态内联。我们先考虑单态内联是什么样子:
monomorphic
1 | function f(o) { |
用漫画来解释一下:

由于 Slot 只储存{ x: * } 一个IC,因此叫做单态( monomorphic )缓存。但是如果出现 map 不一样的 Object 呢?
polymorphic
1 | function f(o) { |
还是用漫画来解释一下:

因此可以看出,多态指的是多个 shape: 在上述代码中,缓存条目增至两个,分别为 {x: *} 以及 {x: *, y: *}。
这看起来就像是: 在一个函数中,每一个形状的 Object 均会对应一组 IC,也就是说,对于上述代码来说,IC 条目为:
slot | state | shape | offset
—|—|—|—
0 |polymorphic| map1 | x.offset
1 | polymorphic | map2 | x.offset
然而,对于以下情况:1
2
3
4
5
6
7
8
9
10
11
12function ff(b, o) {
if (b) {
return o.x
} else {
return o.x
}
}
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })
看起来像是
slot | state | shape | offset
—|—|—|—
0 |polymorphic| map1 | x.offset
1 | polymorphic | map2 | x.offset
然而仔细研究就会发现: 在 then 逻辑中,o.x 的缓存 shape 只有一种 {x:*}; 在 else 逻辑中 o.x 的缓存 shape 也只有一种{ x:* , y:* }。因此,o.x 并非多态 IC,即针对每个分支分别有 monomorphic state的 IC。在这里要强调的是缓存的作用域问题: 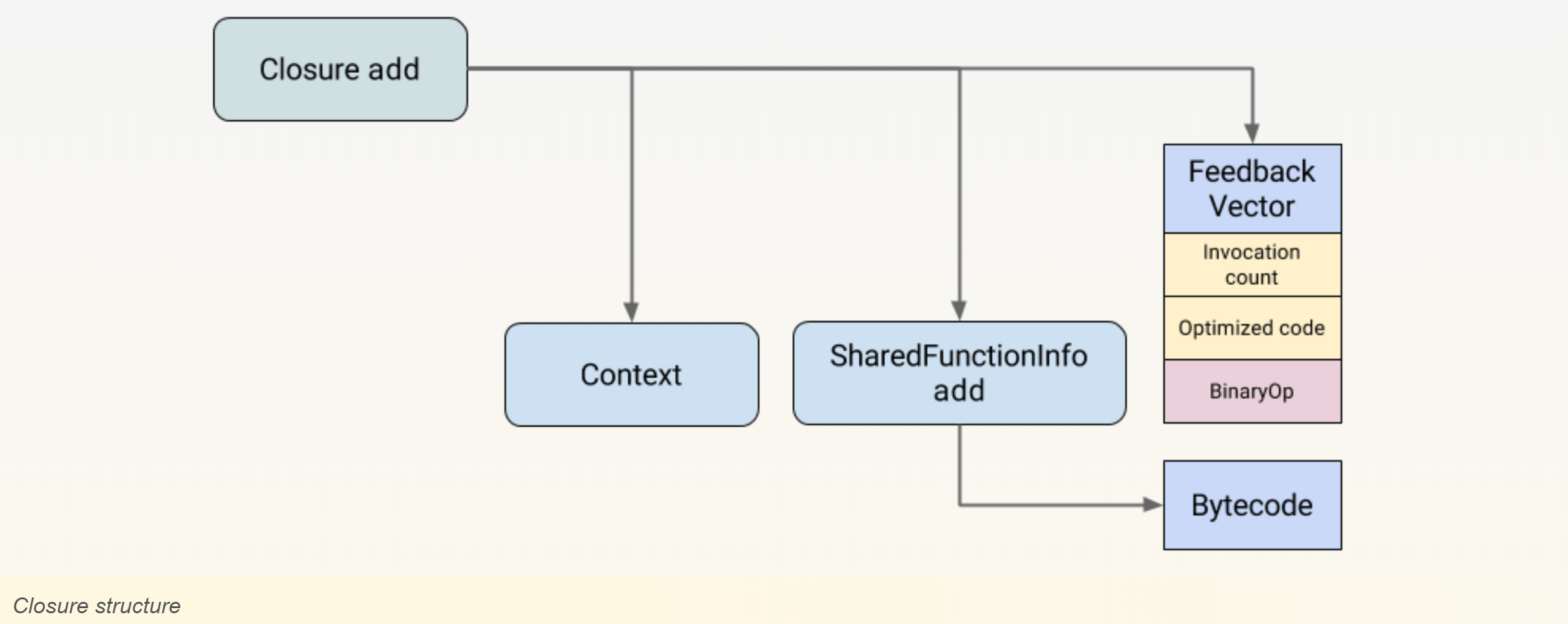
也就是说,每个闭包包含一个 FeedbackVector ,中间包含若干 slots 用来存储 IC。也就是说,then 和 else 分别维护了一个闭包以及 FeedbackVector。内部存储着单态IC。
如果我们继续添加缓存,也就是添加 shape 不同的 IC,比如:
1 | f({ x: 4, y: 1 }) // polymorphic, degree 2 |
则

则超过了阈值( V8: 4 )时,多余的缓存条目将会被扔进一个 global hashtable,这是一个全局 IC 哈希表
特征
- 单态
IC在频繁命中单类型的时候效率最高 - 多态
IC需要在储存的众多IC条目中进行线性搜索 - 对于
global hash类型的IC存储方式,即使没有以上两种快,但性能仍要优于IC缺失状态 IC缺失的状态必须跳转到Runtime重新进行信息收集,代价昂贵。- 采用单态
IC优化最标准的规则就是type-guard + specialized-op的组合 采用多态
IC优化的一般模式是构建map检测的决策树。但对于V8来说,type guard为如下形式:1
2
3
4// Check that o's shape is one of A, B or C - deoptimize otherwise.
$TypeGuard(o, [A, B, C])
// Load property. It's in the same place in A, B and C.
var o_x = $LoadByOffset(o, offset_x)这么做有一个好处就是:如果两个
$TypeGuard(o, [A, B, C])之间没有任何的side effect,那么就可以消除冗杂的TypeGuard(第二个)。也就是说,在这种情况下多态TypeGuard完全是模仿单态TypeGuard工作。
Graph build in turbofan
Turbofan生成graph依赖于Ignition传进来的Bytecode Array,主要的处理流程:
->BytecodeGraphBuilder::CreateGraph()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//bytecode-graph-builder.cc:577
void BytecodeGraphBuilder::CreateGraph() {
SourcePositionTable::Scope pos_scope(source_positions_, start_position_);
// Set up the basic structure of the graph. Outputs for {Start} are the formal
// parameters (including the receiver) plus new target, number of arguments,
// context and closure.
int actual_parameter_count = bytecode_array()->parameter_count() + 4;
graph()->SetStart(graph()->NewNode(common()->Start(actual_parameter_count)));
//维护寄存器文件,上下文
Environment env(this, bytecode_array()->register_count(),
bytecode_array()->parameter_count(),
bytecode_array()->incoming_new_target_or_generator_register(),
graph()->start());
set_environment(&env);
//遍历Bytecode Array
VisitBytecodes();
// Finish the basic structure of the graph.
DCHECK_NE(0u, exit_controls_.size());
int const input_count = static_cast<int>(exit_controls_.size());
Node** const inputs = &exit_controls_.front();
Node* end = graph()->NewNode(common()->End(input_count), input_count, inputs);
graph()->SetEnd(end);
}
->BytecodeGraphBuilder::VisitBytecodes()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//bytecode-graph-builder.cc:875
void BytecodeGraphBuilder::VisitBytecodes() {
BytecodeAnalysis bytecode_analysis(bytecode_array(), local_zone(),
analyze_environment_liveness());
bytecode_analysis.Analyze(osr_offset_);
set_bytecode_analysis(&bytecode_analysis);
interpreter::BytecodeArrayIterator iterator(bytecode_array());
set_bytecode_iterator(&iterator);
···
//iterator遍历式 Visite Bytecode
for (; !iterator.done(); iterator.Advance()) {
VisitSingleBytecode(&source_position_iterator);
}
set_bytecode_analysis(nullptr);
set_bytecode_iterator(nullptr);
DCHECK(exception_handlers_.empty());
}
->BytecodeGraphBuilder::VisitSingleBytecode()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//bytecode-graph-builder.cc:843
void BytecodeGraphBuilder::VisitSingleBytecode(
···
switch (iterator.current_bytecode()) {
#define BYTECODE_CASE(name, ...) \
case interpreter::Bytecode::k##name: \
//visited by bytecode specific visitor for each bytecode
Visit##name(); \
break;
BYTECODE_LIST(BYTECODE_CASE)
#undef BYTECODE_CODE
}
}
}
Deoptimization
在Javascript执行期间有时会触发deoptimization。为了支持deoptimization,BytecodeGraphBuilder需要跟踪interpreter堆栈帧的状态,以便在反优化时重建Interpreter堆栈帧,并在触发deopt的位置重新进入该函数。
environment 追踪了在 bytecode 执行过程中各节点的寄存器信息,并在每个可能触发deopt的节点相关联的FrameState里进行核查。由于bytecode到JSOperator节点之间是一一映射,这也就意味着我们在deopt的时候会返回到某个 Bytecode 位置。因此,我们使用Bytecode offset作为 BailoutId,也就是 bci(见V8 Optimize: FrameState)。
Turbofan 在为 deopt 行为生成对应的处理代码的时候,会基于 deopt 节点的 FrameState 序列化一个 TranslatedState 记录,该记录包含了一些重建解释器运行环境所需的必要信息。一旦触发反优化,turbofan 将会用 TranslatedState 重建解释器运行环境,然后 Runtime 将会用 InterpreterNotifyDeoptimized builtin 重新进入interpreter继续执行 bci 位置的字节码。



