

Intro: Basic Analysis of AFL
AFL 初探
源码分析
1 | static void add_instrumentation(void) { |
afl-as.c文件中插桩的条件:
1 | /* In some cases, we want to defer writing the instrumentation trampoline |
具体看一下插进去的代码是什么:
通过fprintf()将格式化字符串添加到汇编文件的相应位置,只分析32位的情况,trampoline_fmt_32的具体内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static const u8* trampoline_fmt_32 =
"\n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leal -16(%%esp), %%esp\n"
"movl %%edi, 0(%%esp)\n"
"movl %%edx, 4(%%esp)\n"
"movl %%ecx, 8(%%esp)\n"
"movl %%eax, 12(%%esp)\n"
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
"movl 12(%%esp), %%eax\n"
"movl 8(%%esp), %%ecx\n"
"movl 4(%%esp), %%edx\n"
"movl 0(%%esp), %%edi\n"
"leal 16(%%esp), %%esp\n"
"\n"
"/* --- END --- */\n"
"\n";
其中,movl $0x%08x, %%ecx\n 为将R(x)生成的随机数给ecx作为标识代码段的key。然后调用__afl_maybe_log,调用完之后,把栈上保存的值恢复回去,再把栈恢复。
main_payload_32:
1 | static const u8* main_payload_32 = |
特别的,对于llvm模式,代码插桩仅需一个modulepass,对每个 BB 进行 IRB 的辅助插桩即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45for (auto &F : M)
for (auto &BB : F) {
BasicBlock::iterator IP = BB.getFirstInsertionPt();
IRBuilder<> IRB(&(*IP));
if (AFL_R(100) >= inst_ratio) continue;
/* Make up cur_loc */
unsigned int cur_loc = AFL_R(MAP_SIZE);
ConstantInt *CurLoc = ConstantInt::get(Int32Ty, cur_loc);
/* Load prev_loc */
LoadInst *PrevLoc = IRB.CreateLoad(AFLPrevLoc);
PrevLoc->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *PrevLocCasted = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty());
/* Load SHM pointer */
//shared memory table
LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr);
MapPtr->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *MapPtrIdx =
IRB.CreateGEP(MapPtr, IRB.CreateXor(PrevLocCasted, CurLoc));
/* Update bitmap */
LoadInst *Counter = IRB.CreateLoad(MapPtrIdx);
Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1));
IRB.CreateStore(Incr, MapPtrIdx)
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
/* Set prev_loc to cur_loc >> 1 */
StoreInst *Store =
IRB.CreateStore(ConstantInt::get(Int32Ty, cur_loc >> 1), AFLPrevLoc);
Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
inst_blocks++;
}
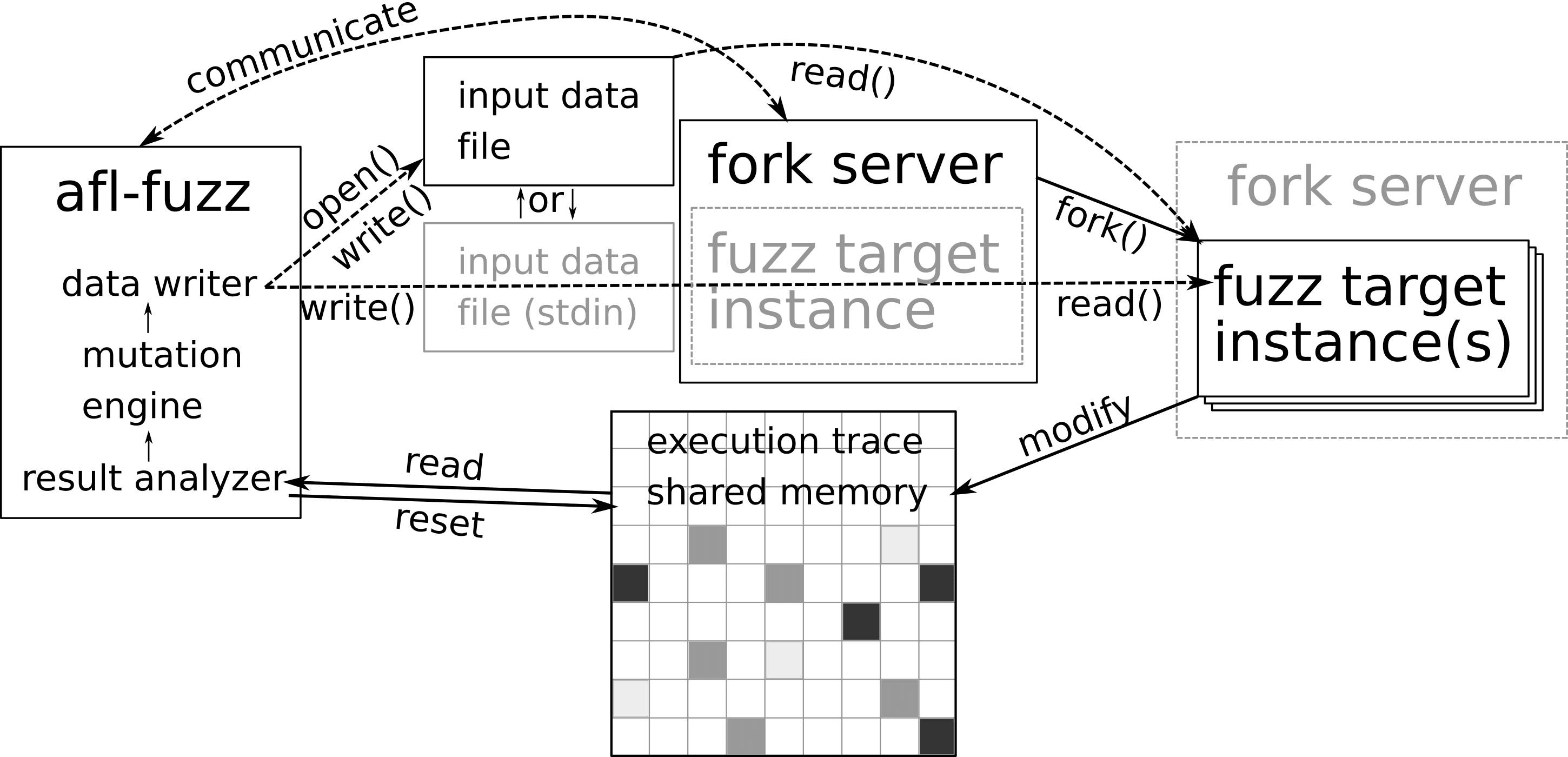
现在在回到fuzz侧,还记得forksrv的wait状态吗?fuzzer对于wait状态的解除是通过进行用例测试,在fork server启动完成后,一旦需要执行某个测试用例,则fuzzer会调用run_target()方法,在此方法中,便是通过命令管道,通知fork_server准备fork;并通过状态管道,获取子进程pid:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if (child_pid <= 0) FATAL("Fork server is misbehaving (OOM?)");
随后,fuzzer再次读取状态管道,获取子进程退出状态,并由此来判断子进程结束的原因,例如正常退出、超时、崩溃等,并进行相应的记录。1
2
3
4
5
6
7
8
9
10
11
12
13 if ((res = read(fsrv_st_fd, &status, 4)) != 4) {
...
/* Report outcome to caller. */
if (WIFSIGNALED(status) && !stop_soon) {
kill_signal = WTERMSIG(status);
if (child_timed_out && kill_signal == SIGKILL) return FAULT_TMOUT;
return FAULT_CRASH;
}
Fork Server(结合上述源码)
【afl-fuzz.cc:!forksrv_pid】fuzzer进程执行fork()得到fork server进程,然后重定向两个管道作为通信接口,并关闭不必要的管道。其中设置了 SAN。然后执行 target。此为forksrv_init
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if (!forksrv_pid) {
...
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
...
close(ctl_pipe[0]);
close(ctl_pipe[1]);
close(st_pipe[0]);
close(st_pipe[1]);
...
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
...
execv(target_path, argv);对于父进程(fuzzer),则会读取状态管道的信息,如果一切正常,则说明fork server创建完成。
1
2
3
4
5
6
7
8
9
10fsrv_st_fd = st_pipe[0]
...
rlen = read(fsrv_st_fd, &status, 4);
...
/* If we have a four-byte "hello" message from the server, we're all set. Otherwise, try to figure out what went wrong. */
if (rlen == 4) {
OKF("All right - fork server is up.");
return;
}
共享内存
作为fuzzer,AFL并不是像无头苍蝇那样对输入文件无脑地随机变化(其实也支持这种方式,即dumb模式),其最大特点就是会对target进行插桩,以辅助mutated input的生成。具体地,插桩后的target,会记录执行过程中的分支信息;随后,fuzzer便可以根据这些信息,判断这次执行的整体流程和代码覆盖情况。
AFL使用共享内存,来完成以上信息在fuzzer和target之间的传递。具体地,fuzzer在启动时,会执行setup_shm()方法进行配置。其首先调用shemget()分配一块共享内存,大小MAP_SIZE为64K:1
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
分配成功后,该共享内存的标志符会被设置到环境变量中,从而之后fork()得到的子进程可以通过该环境变量,得到这块共享内存的标志符:1
2shm_str = alloc_printf("%d", shm_id);
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
并且,fuzzer本身,会使用变量trace_bits来保存共享内存的地址:1
trace_bits = shmat(shm_id, NULL, 0);
在每次target执行之前,fuzzer首先将该共享内容清零:1
memset(trace_bits, 0, MAP_SIZE);
接下来,我们再来看看target是如何获取并使用这块共享内存的。相关代码同样也在上面提到的方法__afl_maybe_log()中。首先,会检查是否已经将共享内存映射完成:1
2
分支信息的记录
[warning] AFL 保存的是 edges 执行次数而不是 blocks 执行次数,AFL是根据二元tuple(跳转的源地址和目标地址)来记录分支信息,从而获取target的执行流程和代码覆盖情况,其伪代码如下:1
2
3cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
其中的代码在上述源码分析中可以找到(包含llvm_pass)
AFL文件变异
这一部分先挖坑,因为没有具体阅读源码,只是收集到的资料,源码部分之后会补上
bitflip
- [自动检测token]: 在进行bitflip 1/1变异时,对于每个byte的最低位(least significant bit)翻转还进行了额外的处理:如果连续多个bytes的最低位被翻转后,程序的执行路径都未变化,而且与原始执行路径不一致,那么就把这一段连续的bytes判断是一条token。
- [生成effector map]: 在对每个byte进行翻转时,如果其造成执行路径与原始路径不一致,就将该byte在effector map中标记为1,即“有效”的,否则标记为0,即“无效”的。
arithmetic
加减
interest
特殊语料库的替换
dictionary
havoc
splice
cycle
一个AFL优化策略
引用:1
2
3
4
5为此,我对ELF文件变异和objdump执行路径变异进行了简单的试验,发现许多”数据“bytes被翻
转后,确实能够引起执行路径的变化。但是,这些”数据“bytes往往是一块块分布在文件中的,
而每一块”数据“中的每个bytes被翻转后,执行路径往往是相同的。所以,我们就有了一个朴素
的想法:如果翻转一个byte引起执行路径变化,而且翻转该byte与翻转其前一个byte的执行路
径不同,此时才将其视为“有效”的。



